Blog
Short story about evading Antivirus Detection
Lately I came across an interesting paper where the authors use Reinforcement Learning (RL) to obfuscate malicious Portable Executable (PE) files to evade detection by antivirus (AV) scanners.
The authors use actions as, for instance, random byte padding, packing the binary, adding benign strings to the .text section, modifying timestamps, adding function imports, etc… to obfuscate the binary file. After applying these actions, the modified PE file will be checked against an AV to see if the detection rate decreases.

The authors’ approach, depicted in the Figure above1, achieves an evasion rate of $100$% after only $5$ actions. As remarkable as this might sound, the authors’ main focus is to evade the detection by Machine Learning (ML) classifiers.
Well, ML models tend to overfit or focus on artifacts 23 which makes an evasion easy, as the authors already state, model evasion tactics could include adversarial samples 1. Furthermore, problems caused by distribution shift are particularly known in the security domain. For example, ML models that attempt to detect vulnerabilities in Source Code 4 tend to perform worse when fed data from distributions other than those on which they were trained.
The interesting part however is that they also use a single non-ML-based commercial AV suite. They reach a $70$% evasion rate against this AV tool. This is particularly interesting because there is a huge market around AV systems and companies pay a lot for commercial licenses.
Classical AV systems try to infer the maliciousness of an executable file by relying on a set of certain techniques 5. The simplest one includes searching for specific patterns and matching them against known signatures.
This can be easily evaded by inserting random NOP instructions. Thus, more efficient scanners preprocess binary files and remove skip/junk instructions (Smart Scanning), known benign code sections (Skeleton Detection), or hash multiple parts of the same malware (Nearly Exact Identification) to improve detection capabilities. State-of-the-art approaches also include heuristic analysis where they scan for suspicious imports (e.g. from Kernel32.dll), or multiple PE Headers. Of course, these are all static methods without relying on a dynamic execution of the inspected sample.
Essentially, it is a cat-and-mouse game between the AV companies and the malware authors.
Motivation
In my PhD, I currently investigate Machine Learning for intelligent static code analysis. My rough idea is, instead of training a RL model to perturb the binary PE file, it may be better to perturb the malware’s source code directly. And since the evasion of ML model detection seems to be trivial, I thought the impact of an high evasion rate for a large amount of commercial AV systems might be much deeper.
Idea
There is an interesting research around the anonymization of code 6. The assumption is, that we can deanonymize the author of a piece of code, for example by looking at his specific coding style. The literature around so called (code) authorship attribution therefore deals with making the attribution of authorship more difficult. My idea is, maybe we can apply the same techniques to evade malware detection by AVs. In particular, we can apply different coding styles to our code, add random functions, change control- and dataflow while pertaining semantics, obfuscate variables and so on. Furthermore, we can use a RL-based or evolutionary algorithms and apply such actions to minimize a cost function just as 2. Clearly, a detection by AV system $x$ positively contributes to this cost. Hence, we can define our cost function simply as: $$ \min_x \mathcal{C}(x) = \sum_{i=0}^n Detect_i(x) $$
With $AV_i$ being the $i$th AV, $x$ being the program and $$Detect_i(x) = \begin{cases} 1 & \text{if } AV_i \text{ detects } x, \\\ 0 & \text {otherwise}.\end{cases}$$
Implementation
Recall that we need to define some kind of environment and actions as depicted in the following Figure 2. The environment constitues a set of AV scanners, while the source code perturbations belong to the actions.
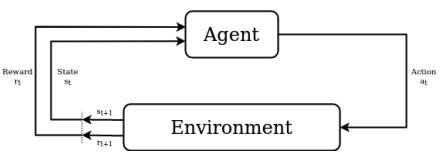
Detection Environment
First, we need a set of AV scanners we can query quickly (as opposed to VirusTotal for example). There is an unmaintained and discontinued VirusTotal clone available, called Malice. Unfortunately, most of it isn’t working anymore.
Therefore, I fixed and recycled as much as I could from Malice to get $14$ commercial and open-source AV systems up and running. You can find them here. Each AV is implemented as a microservice taking a file via http which then returns a detection report.
To try it out you need docker, docker-compose and httpie:
|
|
The environment contains $14$ up-to-date antivirus engines.
Case-Study A
I searched for a few C++ malware repositories on Github that are simple, compileable and Windows targeted. I quickly found Stealer. It only consists of three source files and the payload goes something like this:
- Stealer Copies itself as svchost.exe to some folder.
- Adds a Registry Run key to enable autostart on windows startup.
- Starts a keylogging procedure and takes some screenshots every 50s.
The trojan is far from sophisticated, all strings are clearly readable, it starts a hidden console window, it lacks networking capabilities but besides that, its good for analysis. An already compiled binary is in the repository, which immediately got deleted by my McAfee.
According to VirusTotal 34 out of 62 AV systems correctly detect the sample as malicious.
As a quick side note, people pay a lot of money to find cryptors, packers or obfuscaters that lower the detection rate of their malware. On warez sites, all remote administration tools (RATs) are often praised as being undetected (UD) or even fully undetected (FUD).
Lets add some notion here: Say we have $n$ AV Systems and our malware gets detected by $k \le n$. We can assume that our malware is $k$-Detected. Our sample is FUD if $k=0$ and its UD if $k$ is sufficiently small. Clearly, FUD warez are more expensive than UD warez but the prices are still high nonetheless.
Compilation
Unfortunately, I don’t have a Windows machine. Soooo, we have to cross-compile Stealer with MinGW. And setting up cross-compilation toolchains for C++ does certainly not belong to my favourite tasks. Luckily, there is dockcross that has all needed toolchains in separate standalone docker images. Let’s say we want to compile the malware:
- First we clone Stealer and set up the MinGW toolchain container for x86
|
|
- Then compiling Stealer is as simple as:
|
|
Its as simple as that, you should see stealer.exe appear in the folder. We also have to link against gdi32, since the malware takes screenshots and needs some Windows UI stuff.
The Surprise
Here is where my research prematurely ended, because to my surprise, none of my AV Microservices detects the cross-compiled stealer.exe. And even only $4$ out of $71$ antiviruses detect the sample according to VirusTotal.
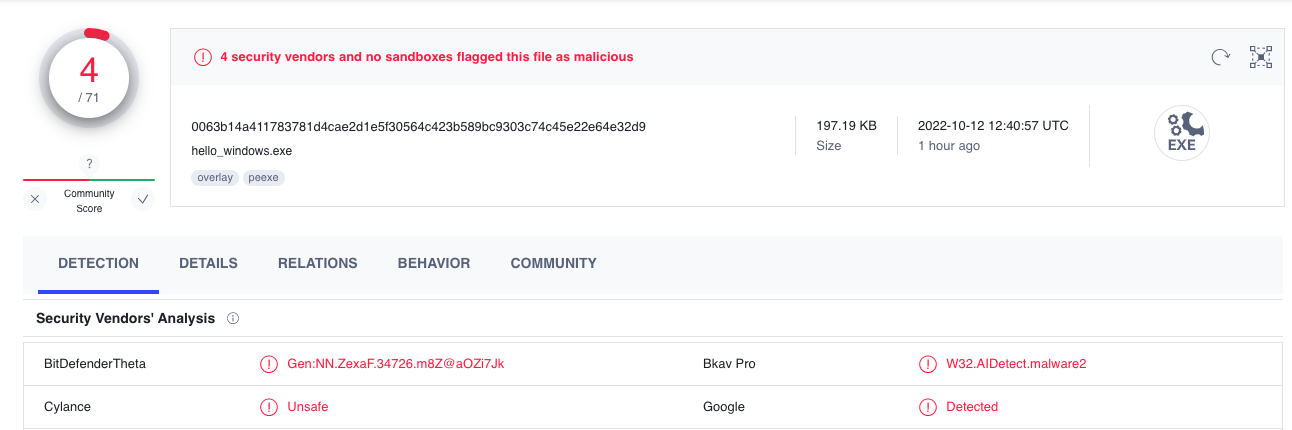
I mean, how am I supposed to evade detection, if it is UD in the first place?
Quick Analysis
Its hard to tell what hinders the detection of the cross-compiled sample. hybrid-analysis is a free online tool which executes a sample and provides dynamic runtime analysis reports. Using this tool, we are able to inspect the interesting memory strings of the Stealer-sample that was already in the repo and the cross-compiled one.
Lets see for the original one:
|
|
And here for the cross-compiled one:
|
|
Seems like the MinGW compiled sample leaves a vastly different memory trace. The two samples also differ in library imports and section layout, while having the exact same capabilities and actions according to hybrid-analysis.
Hybrid-analysis says we are dealing with a Microsoft Visual C++ 8.0 compiled executable for the first sample, but it couldn’t pin-down the compiler for the cross-compiled one.
Here is your first takeaway message: If you want your samples to be UD, just cross-compile them!
Case-Study B
Since the first sample seems to be UD already, I searched for another one. And I found Lilith. Lilith is a remote administration tool and hence more sophisticated than Stealer. Its payload contains networking capabilities, encrypted transfer and a more state-of-the-art persistance routine.
The original MSVC compiled sample has a detection rate of $41$ of $71$ using VirusTotal.
Compilation
To cross-compile Lilith, similar to Stealer, its as simple as:
|
|
After cross-compilation only $8$ VirusTotal AV Scanner detect the sample. But here is the good news: From the $14$ Microservice AV scanner in our environment, Bitdefender is the only one to correctly detect Lilith as Trojan.Generic.31837495 .
The Problem
Having only a single AV detecting the sample degenerates our cost function to $Detect_{Bitdefender} : x \rightarrow [0,1]$ . Instead of a cost function, this function is simply a stop function, since it outputs either $1$ or $0$. That fact renders a reinforcement learning algorithm hardly applicable, since we can’t derive much reward information out of the boolean result.
Now consider our scenario: We want to mutate Lilith’ source code until $Detect_{Bitdefender}=0$. Does that ring a bell? Its simply a mutation-based Fuzzer!
A fuzzer tries to mutate an input $x$ until a program $p$ crashes or hangs. In our case, our program $p$ is simply our environment aka. Bitdefender, the input is the source code of Lilith and the observation is $Detect(x)$.
Experimental Evaluation
The implementation of the fuzzer is quickly done. We have three actions:
- Change Coding Style with clang-format and seven random styles: “LLVM”, “GNU”, “Google”, “Chromium”, “Mozilla”, “WebKit”, “Microsoft”
- A C Code Obfuscator written in Python, randomizing strings, function names, variables and removing whitespaces
- Another Obfuscator written in Python that besides obfuscating identifiers also adds random junk
For reproduction purposes here is the code with the fuzzer and the modified obfuscators.
The fuzzer randomly selects a file and a mutator, mutates the file, compiles Lilith and checks whether Bitdefender is still able to detect it, if so, we repeat.
On average we need $4$ actions until Bitdefender fails to detect it. The action sequences that lead the fuzzer to evade detection, always at least contain two obfuscation steps and $\sim 75$% of the time at least one normalization step.
The first observation is, that apparently the coding style is not important, but part of most action sequences that lead to an evasion.
Interestingly, coding style changes actually affect the compiled output 7. Caliskan et al. investigate whether information pertained after de-compilation still allows to attribute authorship. They find out, that even after stripping off symbol names, it is still possible to detect authorship after de-compilation.
Using code normalization as the only mutator, still causes the Lilith binary hashes to differ.
Consider following three C files in example, the unformatted one is an original sample from the The International Obfuscated C Code Contest, the other two are the same file but formatted with different styles using clang-format.
Compiling the original and a formatted one using the MSVC compiler on Godbolt results in two very different assembly files!
They differ in $605$ places while mostly jump sections are swapped or renamed.
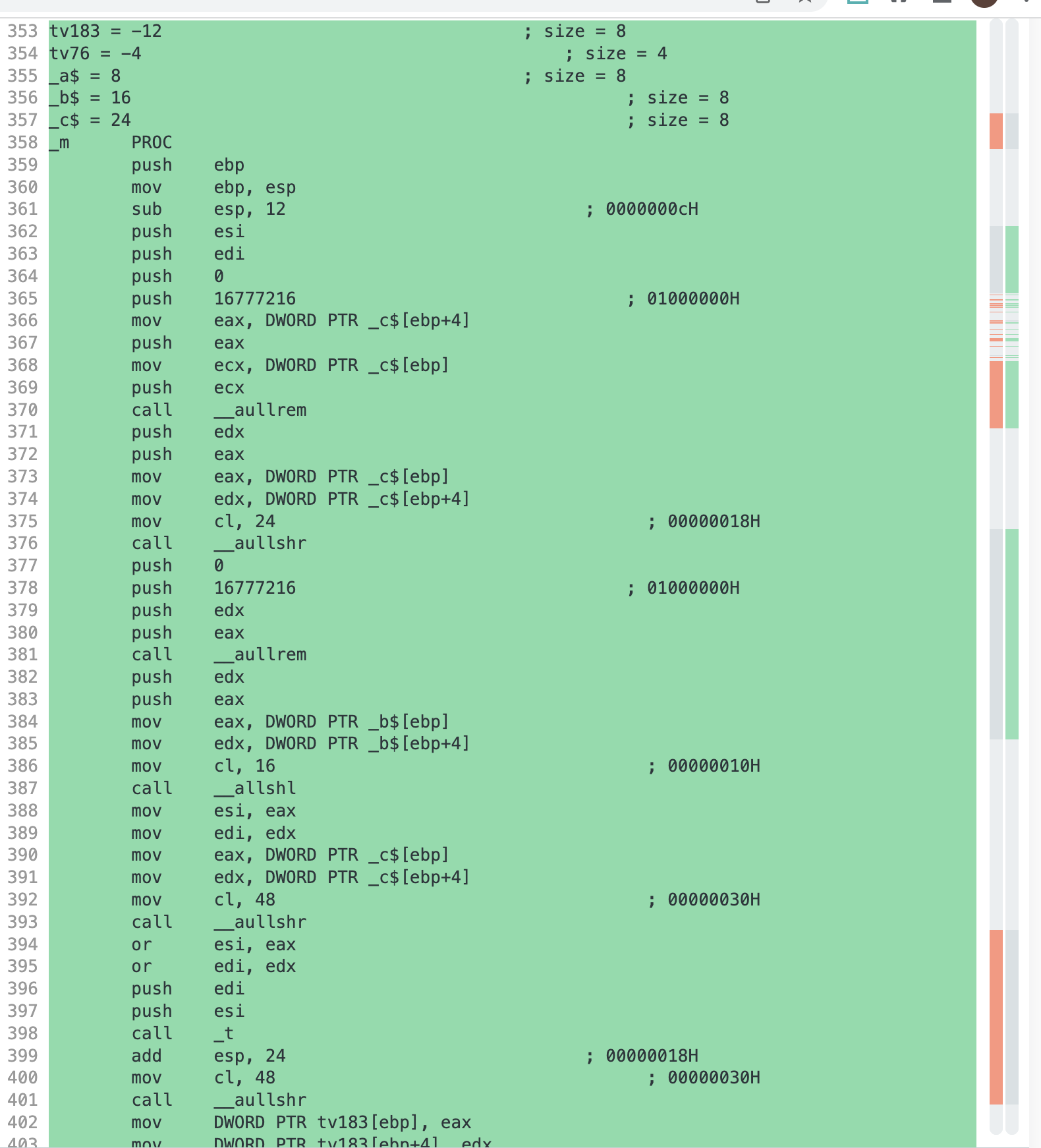
The assembly layout even differs depending on the formatting style. The work8 I introduced in the beginning of this blog post reveals that adding junk sections and renaming sections seem to be very efficient for evading the AVs.
So as a last takeaway message: If you want your Virus to be UD, obfuscate the source code and then normalize it with a coding style.